 TMax: A Simple Recipe for Terminal Agents
TMax: A Simple Recipe for Terminal Agents
Allen Institute for AI · University of Washington
June 16, 2026
TL;DR
TMax is the strongest open RL recipe for terminal agents to date, bringing open data recipes closer to the frontier. We release two things. The first is TMax-15k, a dataset of 14,600 RL environments built from a compositional pipeline with explicit control over difficulty and diversity. It is over 2.5× larger than the next-largest open terminal dataset that releases full environment data. The second is a simple, outcome-only RL recipe (GRPO plus a few stability fixes), which we use to train a family of open models from 2B to 27B.
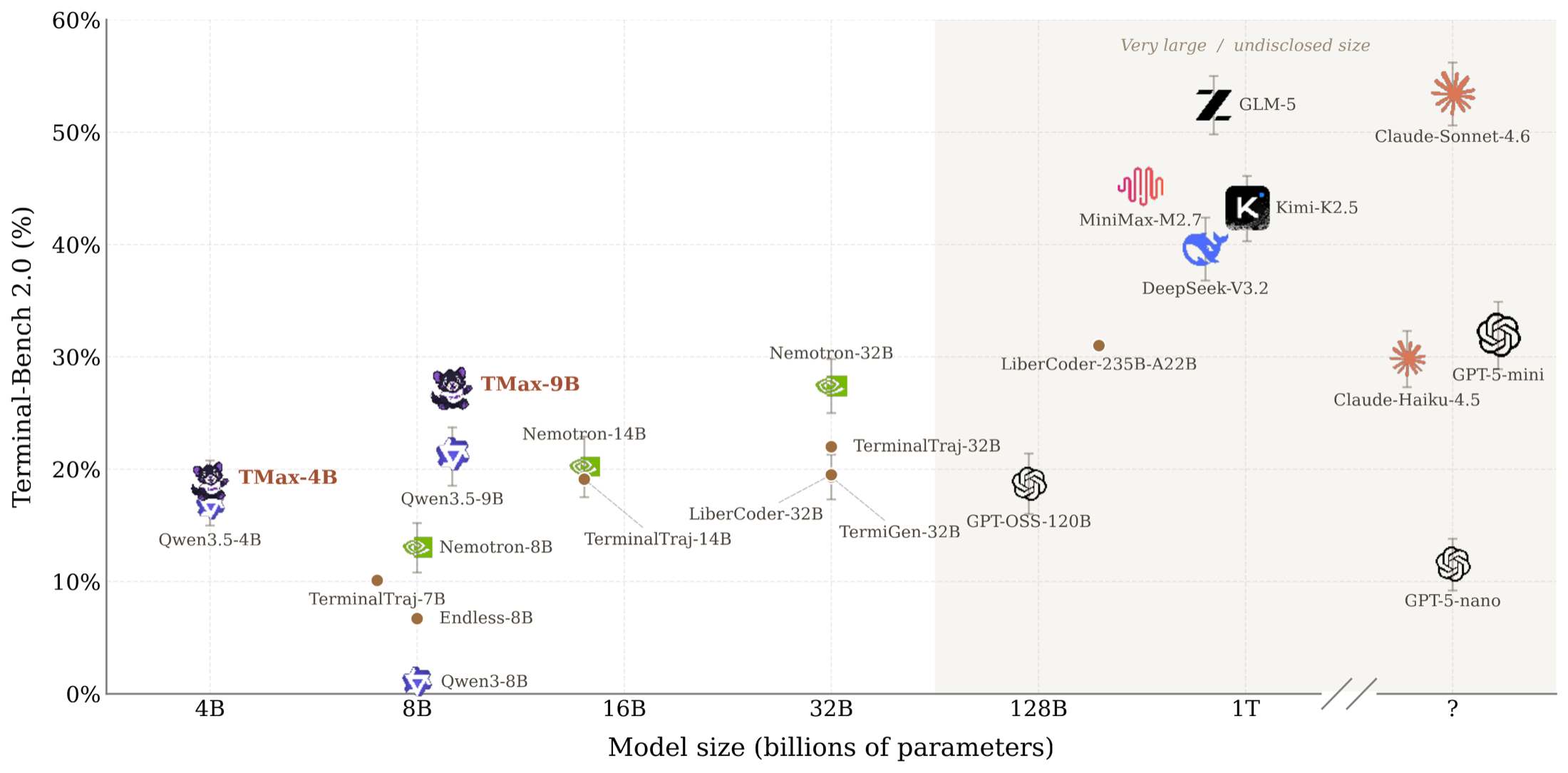
TMax-9B reaches 27.2% on Terminal Bench 2.0. Under official Terminal Bench settings this is the strongest open-weights model under 10B we are aware of: it beats 32B terminal agents from prior work and approaches closed models like Claude Haiku 4.5 (29.8%). Scaling the same recipe up, TMax-27B improves to 42.7%, approaching models 10 to 40× its size like the 1T-parameter Kimi K2.5 (43.2%).
Resources: 📄 Paper · 👨💻 GitHub · 🤗 HF Models · 🤗 HF Dataset · 🐦 Tweet
1. Terminal agents, and why they’re hard to train
Terminal-using agents have quickly become the most popular way people
put language models to work. A terminal agent is a language
model that interacts with a terminal environment: by issuing commands in
a shell, calling tools, reading the output, and iterating. It might
resolve a failing build, profile a slow service, recover a corrupted
archive, or wire up a multi-service stack. The model plans, runs a
command, looks at stdout/stderr, and tries
again. This is now the dominant interface for agentic coding
products,For example, Anthropic’s Claude Code and other
terminal-native coding products.
and the tasks these agents are asked to solve keep
getting more complex and long-horizon.
Despite this popularity, there is surprisingly little open academic work on training terminal agents with RL. We think this comes down to three gaps:
- Hard benchmarks. Evaluations like Terminal BenchMerrill et al., “Terminal Bench,” 2026.
capture genuinely long-horizon, multi-step terminal work, but they are hard, and much prior work sidesteps them in favor of simpler bug-fixing or natural-language-to-bash setups. - A lack of data. Real-world terminal traces are scarce or proprietary, and the synthetic datasets that do exist tend to be small, narrow (mostly file manipulation or one dominant domain), or never release their actual RL environments.
- A lack of a simple baseline recipe. Most data-generation papers stop at supervised fine-tuning; the ones that try RL often report ~1-point gains, leaving little signal for the community to build on.
TMax closes the data and recipe gaps. We provide a large, difficulty-controlled dataset of complex terminal tasks and a simple RL recipe that produces large, reliable improvements of over 5 points on Terminal Bench, with gains that transfer across tasks and harnesses. Our contributions are:
- TMax-15k, a dataset of 14,600 RL environments, over 2.5× larger than prior open terminal datasets and notably harder.
- Open-weights terminal agents at 2B/4B/9B/27B scale, trained on this data. Our best 9B model reaches 27.2% on Terminal Bench 2.0, the strongest open model under 10B we are aware of under official settings.
- A simple, reproducible RL recipe, with all components released for training the models.
- Evidence that terminal RL generalizes across harnesses and across tasks, suggesting the model learns real new skills rather than overfitting a single setup.
2. Generating terminal environments at scale
Training a terminal agent with RL needs a lot of executable environments: each task has to ship with the files, dependencies, and an automated check that verifies whether the agent succeeded. Existing pipelines tend to fall short in three ways. They lean on complex, multi-stage generation that is hard to scale; they produce homogeneous task suites dominated by one or two domains; and they offer little control over difficulty, yielding tasks that are either trivially solved or entirely out of reach.
We propose a simple terminal environment generation pipeline that is
scalable, diverse, and difficulty-aware. We use Gemini-3-Pro as
the generator,We chose Gemini-3-Pro for its strong performance on
Terminal Bench.
and the core idea is simple: compose each task by
hierarchically sampling from a set of structured axes.
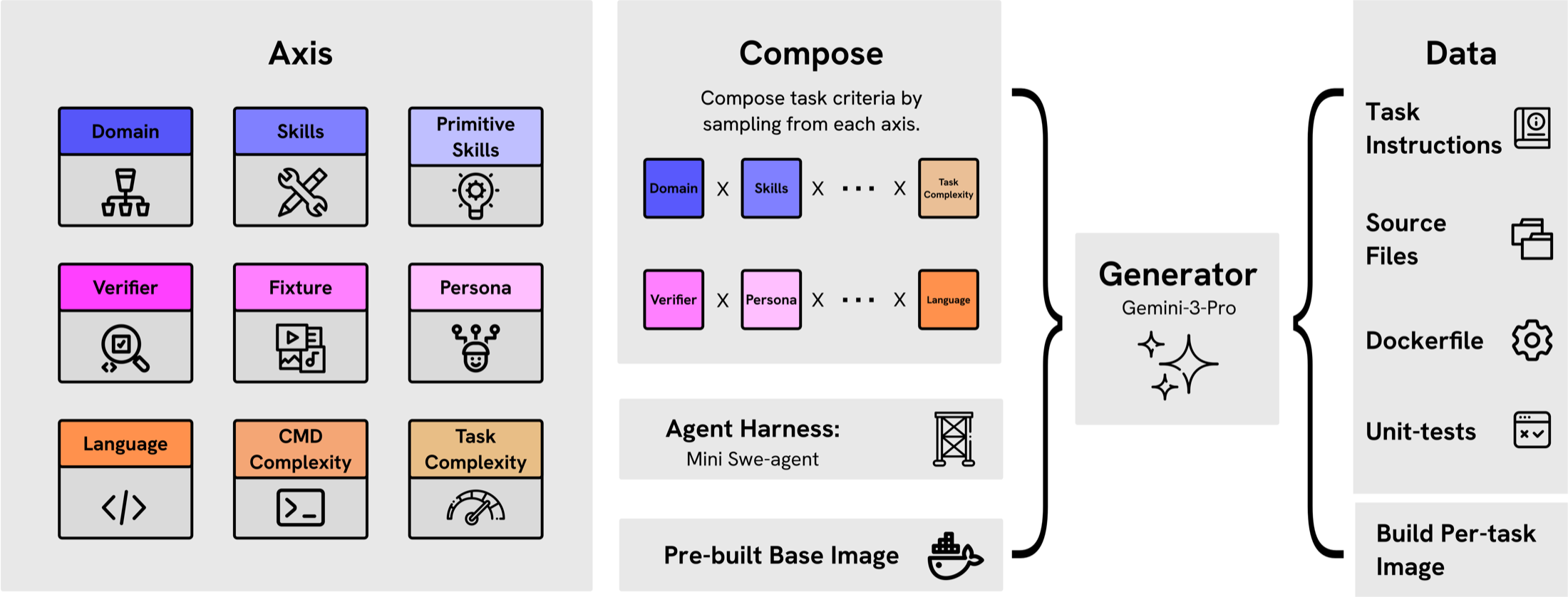
2.1 Generation pipeline
A task is composed by drawing one value from each of nine
structured axes. We follow Nemotron-Terminal to seed the
first two axesPi et al., “Nemotron-Terminal,” 2026. We seed our
domain and skill axes from their taxonomy.
(domain and skills), and introduce six orthogonal axes
targeting diversity and difficulty as shown in the figure above.
Because each task is sampled across these axes, the sampler yields combinatorially many distinct task signatures, while still letting us calibrate each axis on its own. The sampling is hierarchical because a few axes, such as personas and skills, are conditioned on the sampled domain to keep combination compatible. We intentionally make three design choices for the synthetic terminal data generation.
Scalability via soft filtering. Prior pipelines validate every task by having a strong model attempt it for multiple rollouts, which is expensive. We skip that step entirely. Our RL training already does soft filtering for free: it drops any task where all rollouts get the same reward, since those contribute no gradient. In practice the all-zero rate on our data is low (fewer than 8 samples filtered per batch). All we need to guarantee at inference time is that the environment successfully builds, which we do with one Docker image per task (sharing a pre-built base image per domain). Turning two build steps into one allows synthetic environments to scale cheaply.
Diversity via hierarchical sampling. The
hierarchical sampler is itself the main diversity mechanism, and we add
two more. First, we condition generation on domain-specific
personasPersona-conditioned synthesis follows a line of prior
data work, e.g. Ge et al., “Scaling Synthetic Data Creation with
Personas,” 2025.
(6–18 per domain), so that a “red-team operator crafting
an evasion payload” naturally shapes a plausible security task. Second,
we incorporate multi-modal fixtures as part of task
files: PNG, audio file, video, stripped binary, vendored package, etc.
The policy itself stays a text-only model. It inspects and interacts
these artifacts through ordinary terminal tooling (OCR, audio
transcription, ffmpeg).
Difficulty via explicit calibration. To avoid the usual bimodal “trivial or impossible” task split, we calibrate difficulty along two new complexity axes (task complexity, from a handful of commands to intricate 30–60-command workflows, and command complexity, from bash-only to bash + code + system services) and sample uniformly across buckets. We also go beyond exact string-equality checks with graded verifiers: metric thresholds (e.g. accuracy ≥ 0.95), adversarial corpora (accept clean, reject malicious), fuzz equivalence against an oracle, or multi-protocol service checks. Thresholds give a continuous signal for terminal agents to hillclimb, while also increasing turn length.
We release the full set of RL environments as TMax-15K.
2.2 Comparing terminal datasets
We annotated our data and six prior datasets with Gemini-3-Pro and measured difficulty with Gemini-3-Flash (250-task subsample per dataset, 8 rollouts each).
| Dataset | Size | Pass@1 | Pass@8 | Domain balance | Skill balance |
|---|---|---|---|---|---|
| TMax-15k (ours) | 15k | 42% | 53% | 0.998 | 0.732 |
| Endless Terminals | 2.4k | 92% | 95% | 0.481 | 0.284 |
| Open Thoughts Agents | 0.7k | 51% | 60% | 0.292 | 0.153 |
| TermiGen | 3k | 57% | 66% | 0.646 | 0.477 |
| TerminalTraj | 5.5k | 54% | 65% | 0.363 | 0.374 |
| CLI-Gym | 1.5k | 41% | 55% | 0.283 | 0.061 |
| SWE-smith | 59k | 54% | 72% | 0.146 | 0.042 |
Difficulty and balance statistics (Gemini-3-Flash, pass@k as mean over tasks). Balance is a “fraction-of-uniform” diversity score in [0, 1].
Two things worth to note. First, balance. Prior datasets pile 34–95% of their mass onto a single domain (software engineering alone is 95% of SWE-smith), while ours spreads roughly uniformly across all nine. That gives us the highest domain balance (0.998) and skill-type balance (0.732) of any dataset.
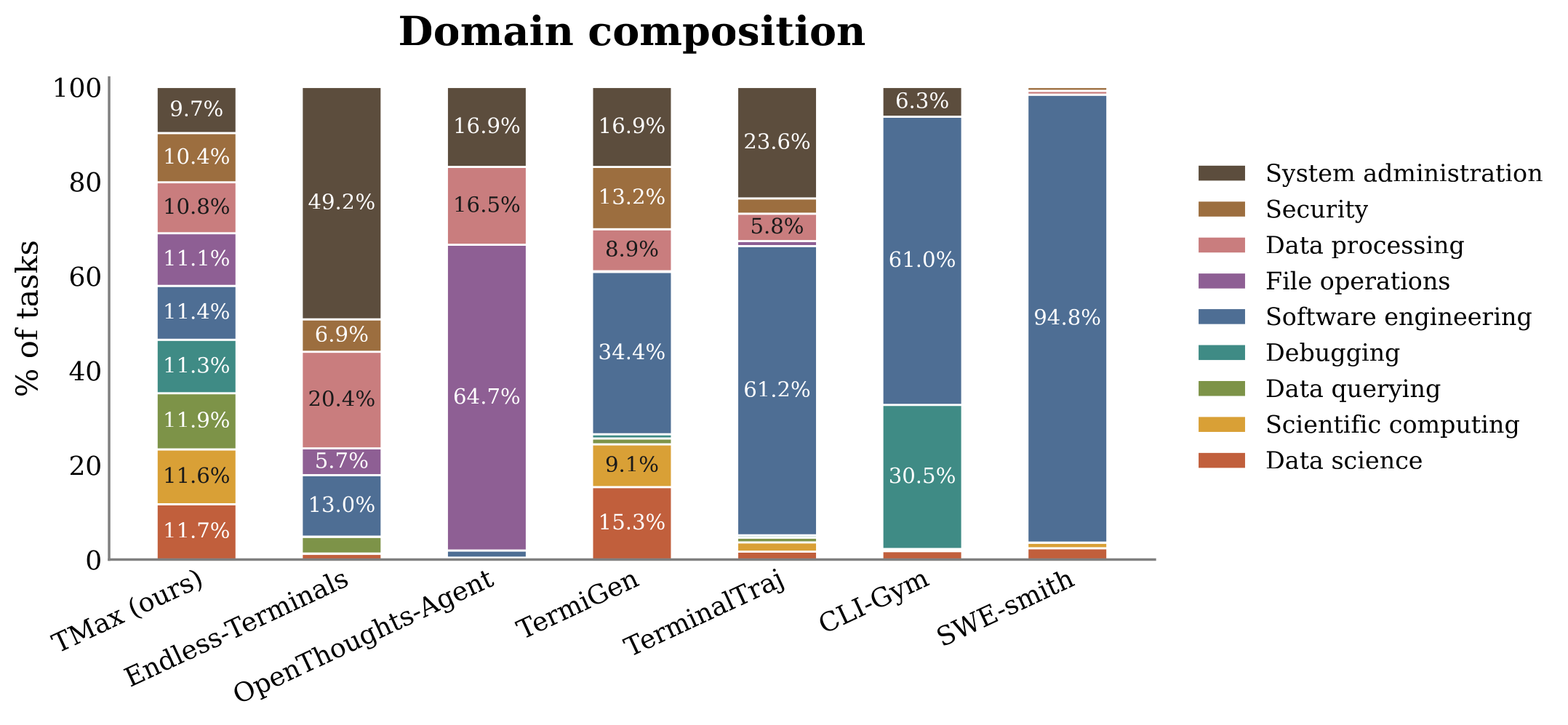
Second, difficulty. Our data is among the hardest of the bunch. Pass@1 is 42% (vs. 41–92% for prior datasets), and it has the lowest pass@8 (53%). The difficulty gap persists even as we draw more rollouts, so the tasks are genuinely hard rather than just high-variance. We also checked for contamination with a 13-gram sliding window against the Terminal Bench tasks and found 0% overlap.
2.3 SFT data and a simple harness
A light SFT warm-up can help stability and performance before
RL,Shown e.g. in DeepSeek-R1 and Olmo 3.
so for our weaker-model experiments on the older Qwen3-8B, we also generate a
small SFT dataset. Reusing the same pipeline, we make 2.2k more
environments and sample 8 trajectories each from Qwen3.6-27B, for 16.5K
trajectories (8K of them successful). We use this SFT data only for the
Qwen3-8B runs, and release it as TMax-SFT-16.5K.
Both data generation and RL rollouts run through a simple harness based on mini-swe-agent with a persistent shell. We found the default Terminus-2 harness more brittle with small models, since it expects the agent to send raw keystrokes.
3. Training TMax with RL
With the data in hand, the question is whether a simple recipe can turn it into a strong agent. We deliberately keep the algorithm plain. The goal is a clean, reproducible testbed with obvious room for future algorithmic improvement.
3.1 Training recipe
We train with a variant of GRPOShao et al., “DeepSeekMath,” 2024.
, outcome-only with no learned reward model, plus a
handful of changes for stability in the long-horizon agentic
setting:
- DPPO instead of vanilla GRPO.Qi et al., “Rethinking the Trust Region for LLM RL”
(DPPO), 2026.
DPPO masks tokens where the inference (vLLM) and training logprobs disagree, using a binary approximation of the total-variation divergence. This small change meaningfully tames training collapse. - A token-level loss,Token-level loss as in Yu et al., “DAPO,” 2025.
fully asynchronous training, filtering of zero-standard-deviation groups, and active sampling to keep batches full.Following Olmo 3.
- An FP32 LM head, keeping the language-model head in full precision to minimize the train/inference mismatch. This mattered most for the hybrid Qwen3.5 models.
Infrastructure-wise, we extend open-instruct, use vLLM for rollouts, and run sandboxes via Podman or Apptainer. A typical run uses 2 nodes for training and 6 for inference on H100s, and takes 2–3 days. The key hyperparameters are:
| Hyperparameter | Value |
|---|---|
| Training steps | 500 |
| Group size | 32 |
| Prompts per batch | 8 |
| Max context length | 65,536 tokens |
| Max tool calls per episode | 64 |
We keep thinking on intermediate turns (“interleaved thinking”), and evaluate on Terminal Bench 2.1 and Terminal Bench Lite, averaging over 3 runs.
3.2 TMax-15K outperforms other terminal data
We first hold the model fixed (Qwen3.5-9B) and vary only the RL dataset. Training on TMax-15k gives the strongest Terminal Bench performance of any dataset we tried. We release the resulting model as TMax-9B.
| RL dataset | TB Lite | TB 2.1 |
|---|---|---|
| None (Qwen3.5-9B) | 41.9 | 16.1 |
| TermiGen | 49.4 | 25.1 |
| Endless Terminals | 52.6 | 25.5 |
| OpenThinker-Agent | 53.0 | 25.1 |
| TerminalTraj | 45.8 | 18.0 |
| CLI-Gym | 50.7 | 25.1 |
| SWE-Smith | 47.2 | 21.0 |
| TMax-15k (ours) | 57.2 | 28.8 |
RL on Qwen3.5-9B across datasets; mean over 3 runs. Our data improve Terminal Bench 2.1 by nearly 13 points over the base model.
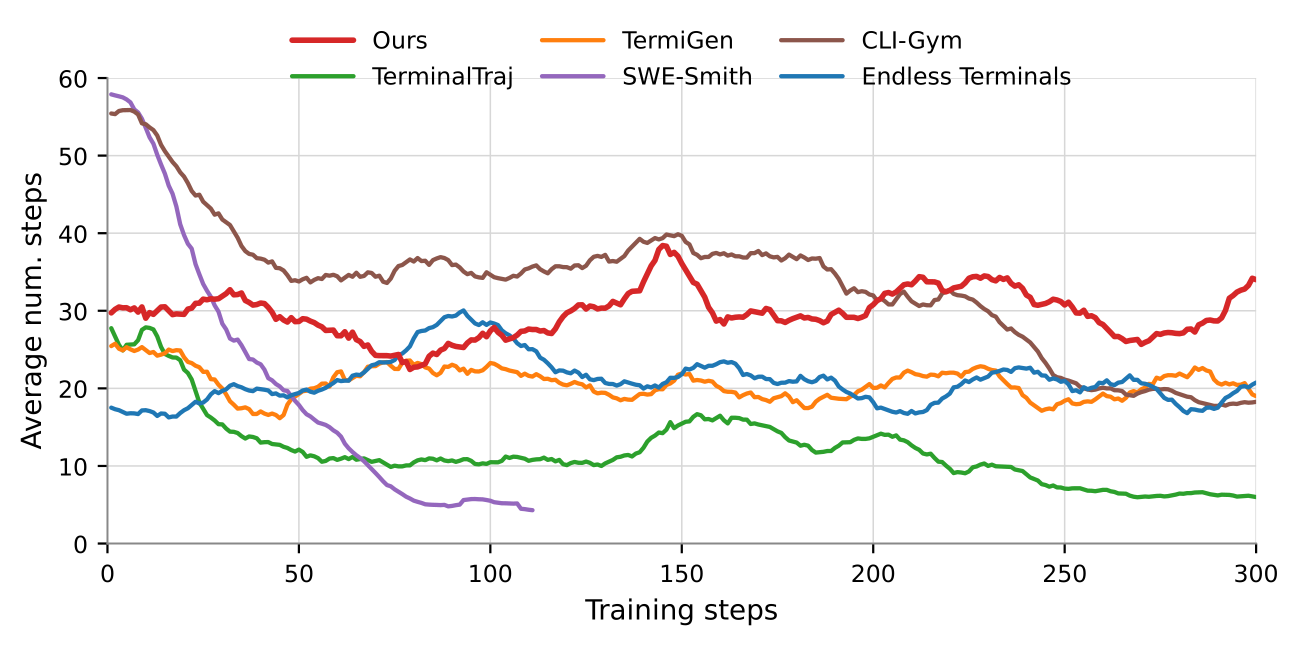
We find that TMax-15K stays difficult throughout training. If we plot the average number of steps the model takes during training, TMax-15k consistently drives more steps per episode than other datasets. The tasks keep demanding real, multi-step work rather than being solved in a couple of commands.
We also see the model learn to think more over the course of training: the number of tokens it spends per assistant turn, for both reasoning and tool-calling, climbs steadily. This is the agentic analogue of inference-time reasoning scaling, and it tracks the model’s improving performance.
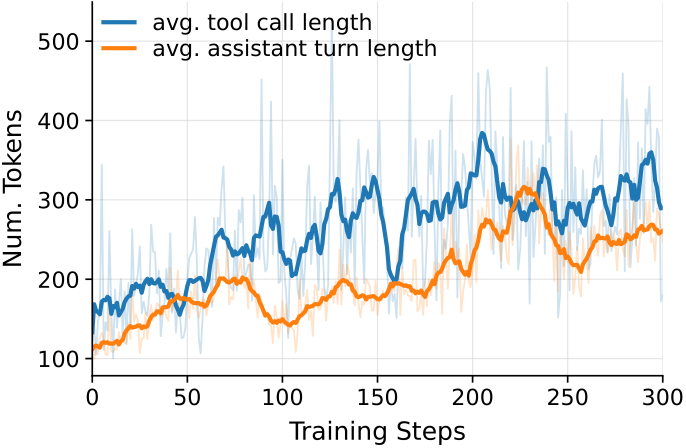
3.3 TMax-9B outperforms prior small terminal agents
At 27.2% on Terminal Bench 2.0, TMax-9B is the best
open-weights model under 10B we compare against under official Terminal
Bench settings,Terminal Bench scores can be sensitive to harness and
timeout settings. With non-standard settings (for example, overriding
the default timeouts) the base Qwen3.5-9B can score noticeably higher,
so we report all numbers under official Terminal Bench settings for a
fair comparison.
beating 32B terminal agents from several prior works and
approaching closed offerings like Claude Haiku 4.5 (29.8%).
The same recipe scales across the whole Qwen3.5 family. TMax-2B and TMax-4B reach 2.9% and 18.9% (from 2.3% and 16.6%), and TMax-27B (built on Qwen3.6-27B) reaches 42.7% (from 39.6%). At that size, TMax-27B approaches models that are a few order of magnitude larger, like the 1T-parameter Kimi K2.5 (43.2%) and the 230B MiniMax M2.7 (45.1%).
3.4 Generalization across tasks, harnesses, and models
Finally, we show our training and data recipe generalizes well across three important axes: tasks (i.e., what it is asked to do), harnesses (i.e., what tools and prompts it is provided when performing tasks), and model families (i.e., the starting point model).
Across tasks. Evaluating TMax-9B beyond Terminal Bench, performance improves across the board, including on a non-agentic math benchmark:
| Benchmark | Qwen3.5-9B | TMax-9B |
|---|---|---|
| SWE-Bench Verified | 44.0 | 53.5 |
| AIME’24/25 (terminal-agent) | 73.3 | 91.1 |
Generalization to other tasks; mean over 3 runs. RL on terminal data improves an agentic SWE benchmark by ~9 points and math by ~18.
Across harnesses. When we swap out the harness for different prompts and tools than the one used during RL, TMax-9B improves by roughly 9 to 15 points in every harness we tried, even ones it never saw in training.
| Harness | Qwen3.5-9B | TMax-9B |
|---|---|---|
| Ours (mini-swe-agent + persistent shell) | 41.9 | 57.2 |
| OpenHands | 36.0 | 46.9 |
| mini-swe-agent | 44.1 | 55.3 |
| Terminus-2 | 36.4 | 45.3 |
Terminal Bench Lite across evaluation harnesses; mean over 3 runs.
Across models. We also apply it to the older Qwen3-8B, with a short SFT warm-start and shorter context. It improves substantially on Terminal Bench Lite (7.3 → 17.7), though gains on the harder Terminal Bench 2.1 are smaller, since at this scale the benchmark’s difficulty makes improvements hard to see.
| Model | TB Lite | TB 2.1 |
|---|---|---|
| Qwen3-8B | 7.3 | 1.1 |
| + SFT | 11.5 | 6.0 |
| + RL | 17.7 | 5.2 |
Qwen3-8B on Terminal Bench Lite and 2.1 after SFT and then RL; mean over 3 runs.
Taken together, these results strongly suggest that TMax RL training teaches the model new, transferable terminal skills, not mere harness-fitting or overfitting to Terminal Bench-style tasks.
4. Analysis & discussion
Two findings shaped the TMax recipe, and we think both are useful for the community training terminal agent in this setting.
4.1 Strong models don’t always want your SFT data
Common post-training pipelines advise warm-start RL with SFT for training stability. However, we find that existing datasets degrades Qwen 3.5’s performance, likedy due to the model undergoing heavy post-training already. This holds even for our own mixture, which we generated from a strong Qwen3.6-27B teacher. The older Qwen3-8B, by contrast, clearly benefits from the same SFT.
| Model | TB Lite | TB 2.1 |
|---|---|---|
| Qwen3.5-9B | 41.9 | 16.1 |
| + TMax SFT | 35.5 | 15.0 |
| + large SFT | 31.3 | 16.9 |
| Qwen3-8B | 7.3 | 1.1 |
| + TMax SFT | 11.5 | 6.0 |
| + large SFT | 16.4 | 7.9 |
SFT before RL helps the older model but hurts the stronger one.
We suspect the larger mixtures lean on relatively weak teacher models from prior work, and that a heavily post-trained model has less to gain and more to lose from imitation. We leave further exploration of good SFT mixtures for Qwen 3.5 as future work.
4.2 Terminal-agent RL is hard to stabilize
We found training was frequently unstable and often collapsed past 200–300 steps. The main culprit is numeric mismatch between training and inference, which the hybrid Qwen3.5 architecture makes worse. Keeping the LM head in FP32 removes the worst logprob spikes (below), and moving from GRPO to DPPO, together with a larger group size, further limits collapse. Long horizons (often 20+ steps) and infrastructure load from running many sandboxes make things harder still. We give the full analysis, including the GRPO-vs-DPPO and group-size comparisons, in the paper.
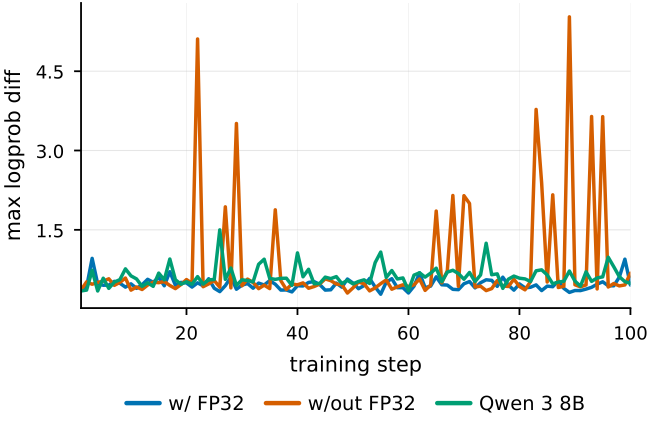
We saw the same instabilities on Qwen3-8B, so this is not a quirk of one model family. We believe more stable, longer training would yield substantially better models.
5. Conclusion
TMax is a simple recipe for training strong terminal agents at small scale. Its two pieces are TMax-15k, a difficulty- and diversity-controlled dataset of 14,600 RL environments, and a plain DPPO training recipe. Together they are enough to train TMax-9B and TMax-27B, which is among the strongest open-weights models under 10B and 30B at the time of writing, respectively. The gains transfer to SWE-Bench, to AIME, and across harnesses, which is evidence that the model has genuinely improved at using a terminal rather than memorizing one setup. We release the data, models, and code as a starting point for others.
Where we’d go next. Follow from our results, three directions naturally falls out. Better training stability, more complex harnesses, and more complex data.
We hope TMax serves as a strong baseline and a useful testbed for the community to improve the stability, performance, and efficiency of terminal agents.
Acknowledgements
TMax is a collaboration between the University of Washington and the Allen Institute for AI (Ai2). We thank members of UW NLP and the Open Ecosystem team at Ai2 for feedback and discussion throughout this project, Michael Noukhovitch for useful discussions on RL stability, and the Ai2 Beaker team for help with infrastructure.
Citation
Please cite this work as:
Ivison, Hamish and Yin, Junjie Oscar and Shao, Rulin and Xiao, Teng and
Lambert, Nathan and Hajishirzi, Hannaneh, "Tmax: A simple recipe for terminal
agents", arXiv preprint arXiv:2606.23321, 2026.Or use the BibTeX citation:
@misc{ivison2026tmaxsimplerecipeterminal,
title={Tmax: A simple recipe for terminal agents},
author={Hamish Ivison and Junjie Oscar Yin and Rulin Shao and Teng Xiao and Nathan Lambert and Hannaneh Hajishirzi},
year={2026},
eprint={2606.23321},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2606.23321},
}